
The more we've worked with AI agents throughout the software development lifecycle, the more apparent one property of their output has become: regardless of whether an agent is provided strong context or weak context, the artifact produced looks just as complete and accurate, at the moment of delivery. The gaps become visible only when someone exercises the artifact: a code reviewer, a QA engineer, a developer trying to extend the work. For code, these gaps may not surface until it's running in production. For a technical design or a PRD, they could show up in any downstream project phase. But at the moment of handoff, the two deliverables are nearly indistinguishable.
This matters because engineers have strong intuitions about what bad work looks like. Bad work looks incomplete, or hasty, or obviously wrong. Agent output doesn't fit that pattern. It looks finished and coherent regardless of whether it's correct. Agents also disguise their bugs in ways that are distinct from what engineers are used to. When an engineer doesn't understand an area of the system, they typically ask questions, flag uncertainty, or leave visible gaps in their work. An uninformed AI agent does none of those things by default. It infers the most plausible answer from its general knowledge and presents that inference as fact. The result is that engineers reviewing agent output are forced to second-guess not just the code, but the factual claims embedded in the output (which service owns which behavior, which schema field maps to which concept) in a way they are not accustomed to doing when reviewing a colleague's work.
In our first post in this series, we wrote about designing agents that stop and ask for guidance, building checkpoints into agent skills so that uncertainty gets surfaced before it compounds into bigger issues in the final artifact. Checkpoints catch the failures that stem from missing context. This post is about the upstream lever: feeding agents the necessary context to prevent those failures in the first place.
The diagram below outlines the general structure of AI-assisted software development workflows.
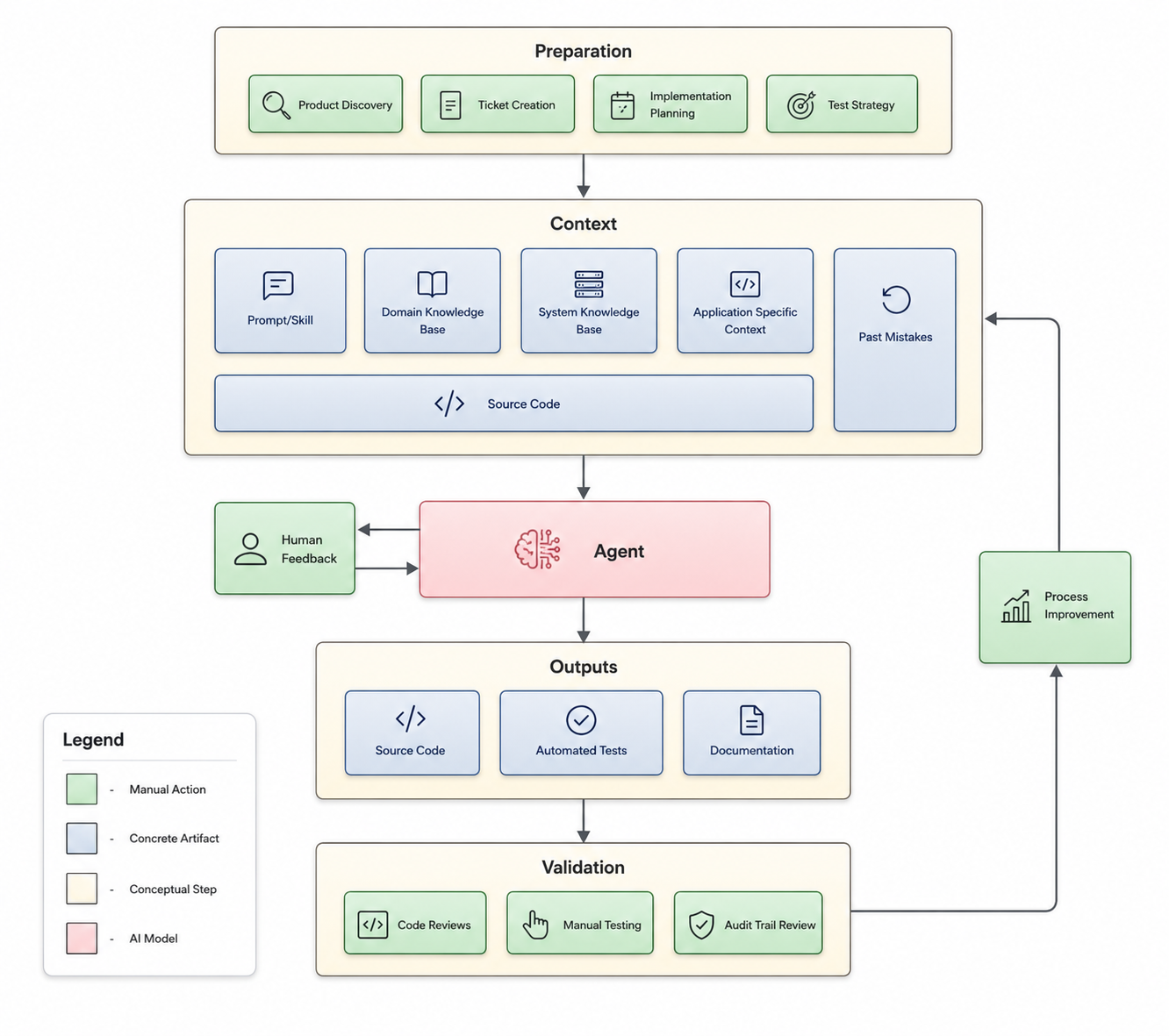
We'll dive deeper into each of the core context sources and the role they play in guiding the agent's decisions and the quality of its output, but first let's look at the two main failure modes that arise from weak context.
Incomplete but Accurate
When context is factually correct but missing pieces, these gaps tend to propagate into the output. Agents do not naturally probe or question the material they are given. They work with what they have, and where the context is silent, they tend to either leave those dimensions unaddressed in the artifact or adopt the simplest interpretation available — not through careful reasoning about trade-offs, but because nothing in the context prompted a different path. This is something engineers naturally compensate for: encountering an unfamiliar area, they dig in, ask questions, and seek out what they need to do the work properly.
The result is an artifact that looks complete on the surface. Overlooked requirements and unaddressed edge cases are not highlighted as gaps; they simply aren't present. The output presents as though they were never in scope. A senior engineer reviewing the work can often spot what's missing because they carry domain context the agent never received, but the artifact itself gives no signal that anything was left out.
What makes this failure mode more manageable than the one below is that the gaps, once identified, are often recoverable. Missing functionality can be added; an overlooked edge case can be addressed. The work is incomplete but the content produced is not technically incorrect.
Comprehensive but Inaccurate
The second failure mode is more damaging. When context is comprehensive but contains factual errors, the agent works from a false premise. Wrong assumptions don't stay where they were introduced. They get referenced by subsequent decisions, treated as established facts, and eventually woven into the core design. By the time the error surfaces, it may look entirely unrelated to the original context mistake.
What makes this failure mode particularly hard to catch is that agents present all information, whether they have strong grounds for it or not, with the same high degree of confidence. Human engineers naturally calibrate their certainty based on how directly they've verified a fact. Information they've checked first-hand is presented differently from information they were simply told. Agents make no such distinction. They present inferred information with at least as much confidence as verified information, and often more. The result is that inaccuracies in the context get carried through into the output with no indication that anything was ever uncertain.
Shi et al. (2023) tested what happens when wrong or irrelevant information is included in the context given to a model. In most of the prompting approaches they evaluated, accuracy fell below 30%. The models didn't ignore the bad context; they reasoned from it and produced confident output that was wrong.
Chari and Agrawal (2018) found the same asymmetry in requirements engineering: incorrect requirements generate cascading defects and trigger new requirements downstream. The resolution of incomplete requirements, by contrast, tends to be more contained.
Incorrectness compounds. Incompleteness is recoverable.
Both failure modes point back to the same upstream question: what did the agent actually know when it started work? That question has a practical answer. There are five sources of context that are worth specific consideration in software engineering workflows. Each one has failure patterns of its own, and a measure of quality that determines whether it helps the agent or misleads it.
Skill / Prompt
A skill is the instruction set the agent works from: what the task is, what intermediate outputs to produce, what the final artifact should look like. It points the agent in the right direction before it makes a single decision. When a skill is well-written, the agent's choices align with what the team would have endorsed. When a skill is vague, the agent exercises its own judgment on decisions that should never have been the agent's to make.
The gap is easy to underestimate until you've seen it concretely. When standing up a code-writing skill for a large, established codebase, the first version of that skill focused on understanding the acceptance criteria for the assigned task, translating those into a clean, simple design, and producing an implementation. That seemed reasonable on the surface. However, when we started working with it, we quickly found it was missing an important step: reviewing existing functionality in the codebase to maintain consistency with established coding practices and design approaches. This is something engineers naturally do when working on any task in even a modestly large codebase. Unless directly instructed to do so, the agent will only intermittently perform this step.
The measure of quality for a skill isn't detail for its own sake. A skill should be specific enough to constrain the decisions that matter, and no more rigid than that. Over-specified skills prevent the agent from exercising judgment in areas where its judgment is actually useful.
Domain Knowledge Base
Domain knowledge is the context for the domain the system operates within: what terminology means in this specific organization/industry, the relative importance of quality attributes within the system, how the team approaches its work, and what processes govern how decisions get made. It is the kind of knowledge a new engineer absorbs slowly over months of conversations with colleagues, and it is almost never written down in a form an agent can navigate.
Agents don't absorb conventions through osmosis. An agent that doesn't know what a particular business term means in this specific domain, or how this team handles escalation decisions, will infer definitions from its training data. That inference may be close enough to be plausible, while also being wrong enough to cause real problems. A glossary of domain-specific terms, paired with documentation of how the team actually works, gives the agent the same orientation a thorough onboarding would give a new hire.
The measure of quality here is accuracy over completeness. A domain knowledge base that covers the most critical terms and processes correctly is more valuable than a comprehensive one with stale or inconsistent entries.
System Knowledge Base
System knowledge is the technical understanding of the system: how it is architected, what each service does, how they interact, and how features cut across multiple services to deliver end-user value. This is the knowledge that determines whether the agent can navigate the codebase at the level of an experienced, senior-level architect, or simply a well educated but inexperienced coder.
We've found it helpful to organize this information along three interrelated dimensions.
- Service-level documentation: Answers the question "what does each component of the system do?"; captures the purpose, structure, and key integration points for each service, application, or repository.
- Feature-level documentation: Answers the question "how does each functional concept work across the system?"; identifies the services that support a feature, its key business rules, and where to find the relevant code.
- Project-level documentation: Answers the question "what is being built right now and what's it's current status?"; provides references to the specific planning artifacts and tickets for in flight work the agent should be aware of.
An agent with access to structured knowledge of this type can navigate from "I need to understand how user authentication works" to specific files, schemas, and integration points across multiple services without searching blind. As Liu et al. (2023) showed, even when relevant information is technically present, performance degrades significantly when it is buried in a large undifferentiated context; indexed structure is what makes the knowledge usable.
The measure of quality for system knowledge is how up to date it is. Stale architecture documentation is an instance of the "comprehensive but inaccurate" failure mode: it covers the subject matter with wrong information. In a fast-moving codebase, outdated system knowledge quickly becomes worse than no system knowledge.
Application-Specific Context
Application-specific context is the collection of best practices and standard operating procedures for a particular codebase: which libraries to use, which patterns to follow, which anti-patterns to avoid. It often lives in a CLAUDE.md or AGENTS.md file and the documents those files reference, but can also be found in code comments, providing helpful guidance to humans and agents alike when working in a specific area of the codebase.
The measure of quality is specificity. An instruction to the agent to avoid a specific pattern with an alternative to use instead is actionable. An instruction to "Follow team conventions" is not.
Past Mistakes
The first four context sources are well-represented in the growing body of writing on context engineering. This one is not, and in our experience it is often the most valuable of all.
The agentic coding workflow has a natural feedback loop built into it: code reviews, QA, and project retros regularly surface issues that trace back to how the agent interpreted its context. Most teams treat these findings as one-off corrections. Fix the bug, move on. Few teams route those failures back as maintained context for the agent to avoid in future sessions.
The principle is straightforward. When a downstream phase catches an issue that traces to an agent decision, that failure belongs in a document the agent reads next time: "In situation X, the agent did Y. The correct behavior is Z." Some teams implement a version of this within a single session, leaving failed attempts visible in the conversation so the agent can see what didn't work. That is valuable. What we've found valuable is to elevate this information into a durable, cross-session knowledge base: a deliberately maintained failure log that grows to incorporate new lessons learned over time, collecting institutional knowledge about what agents tend to get wrong when working in a particular codebase.
This is what the "Process Improvement" loop in the diagram represents. Validation findings don't just inform the next code review. They should improve the context the next agent session works from. Most teams leave that loop empty.
The most direct way to keep agents from making the same mistake twice is to tell them, explicitly, what the mistake was.
The measure of quality for past mistakes context is specificity and recency. "Agent used NewRelic library directly; all reporting events should be routed through the internal ReportingClient library" is actionable. "Agent made mistakes with reporting events" is not. And unlike the other four context sources, this one needs active maintenance.
A past mistakes document is not meant to grow indefinitely. The goal is for each finding to eventually be incorporated back into the appropriate primary context source — the skill, the domain knowledge base, the system knowledge base, the CLAUDE.md — in a thoughtful, maintainable way. The failure log buys time for that incorporation to happen carefully. It captures the finding immediately, when it's fresh, without requiring teams to rework their core context files on the spot. Once an entry has been properly absorbed into the right source document, it can be retired from the log.
In Summary
The reason context engineering is easy to underinvest in is the same reason it matters so much: agents produce an artifact that looks finished regardless of whether the context behind it was adequate. That's the trap. If weak context output looked poor, teams would fix the context. Because it doesn't, teams discover the gaps only when downstream phases exercise the artifact, in QA, in code review, or in production. The five sources of context in this post address that pattern at the root, closing different categories of gap before the artifact ever gets produced.
We'll continue this series with posts on decomposing work into agent-sized pieces, encoding team standards into reusable skills, and building traceability into agent runs.
What's the most valuable piece of context you've added to an agent workflow, and how did you discover it was missing? We'd genuinely like to hear about it. Drop us a line in a comment below or reach out at hello@gobetweenlab.com.
Sources
-
Shi, F., Chen, X., Misra, K., Scales, N., Dohan, D., Chi, E. H., Schärli, N., & Zhou, D. (2023). "Large Language Models Can Be Easily Distracted by Irrelevant Context." Proceedings of the 40th International Conference on Machine Learning (ICML). Retrieved from: https://proceedings.mlr.press/v202/shi23a.html
-
Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2023). "Lost in the Middle: How Language Models Use Long Contexts." Transactions of the Association for Computational Linguistics, 12, 157–173. Retrieved from: https://arxiv.org/abs/2307.03172
-
Chari, S., & Agrawal, M. (2018). "Impact of incorrect and new requirements on waterfall software project outcomes." Empirical Software Engineering (Springer). Retrieved from: https://link.springer.com/article/10.1007/s10664-017-9506-4
